Testing ancient "steppe" samples on PCA together with modern ones revealed unexpected issues. Studies have included different sets of modern samples, some use South Asians samples, but not East Asian ones. Probably they assume that East Asians are not relevant when testing Europeans. Maybe it is not true, because we try to verify thousands of years history and the migration process during that time is always at least partially unknown. Let's look three PCA-runs with different compositions. I published the first one in my previous blog entry, to the second one I include now South Asians and to the third one also East Asians. Due to a limitation of my Gnuplot printing routine to handle populations names I had to remove some ancient and Uralic samples from the printing stage of two global views, but PCA analysis in each phase include all samples creating proper values of x- and y-axes. The Gnuplot routine I use tries to fit all on one page. So I present here two PCA-plots in all three phases, each including global and close-up views. Close-ups include all same global samples and their impact and are made only for better resolution.
In my previous analysis all "steppe" samples located very close modern Europeans. Making it simple let's follow Bronze Age Scandinavians (baSca). They seem to be the westernmost group of all Bronze Age samples.
After adding South Asians all "steppe" samples move eastwards and Bronze Age Scandinavians with them to the same direction. Regarding "steppe" samples this starts to look like
Jones et al. Sorry about flipping pictures, SmartPca does it sometimes.
After adding East Asians changes happen again, "steppe" samples move
back to west and some of Bronze Age Scandinavians are now among Basques (this is interesting indeed, think about western megaliths, but let's forget it now).
As a conclusion I would say that it is not always relevant to make up one's mind about clines between modern and ancient samples if we are not aware of the history between ancient and modern samples. We can select modern samples coincidentally or even in a prejudiced manner and perhaps lose meaningful history.



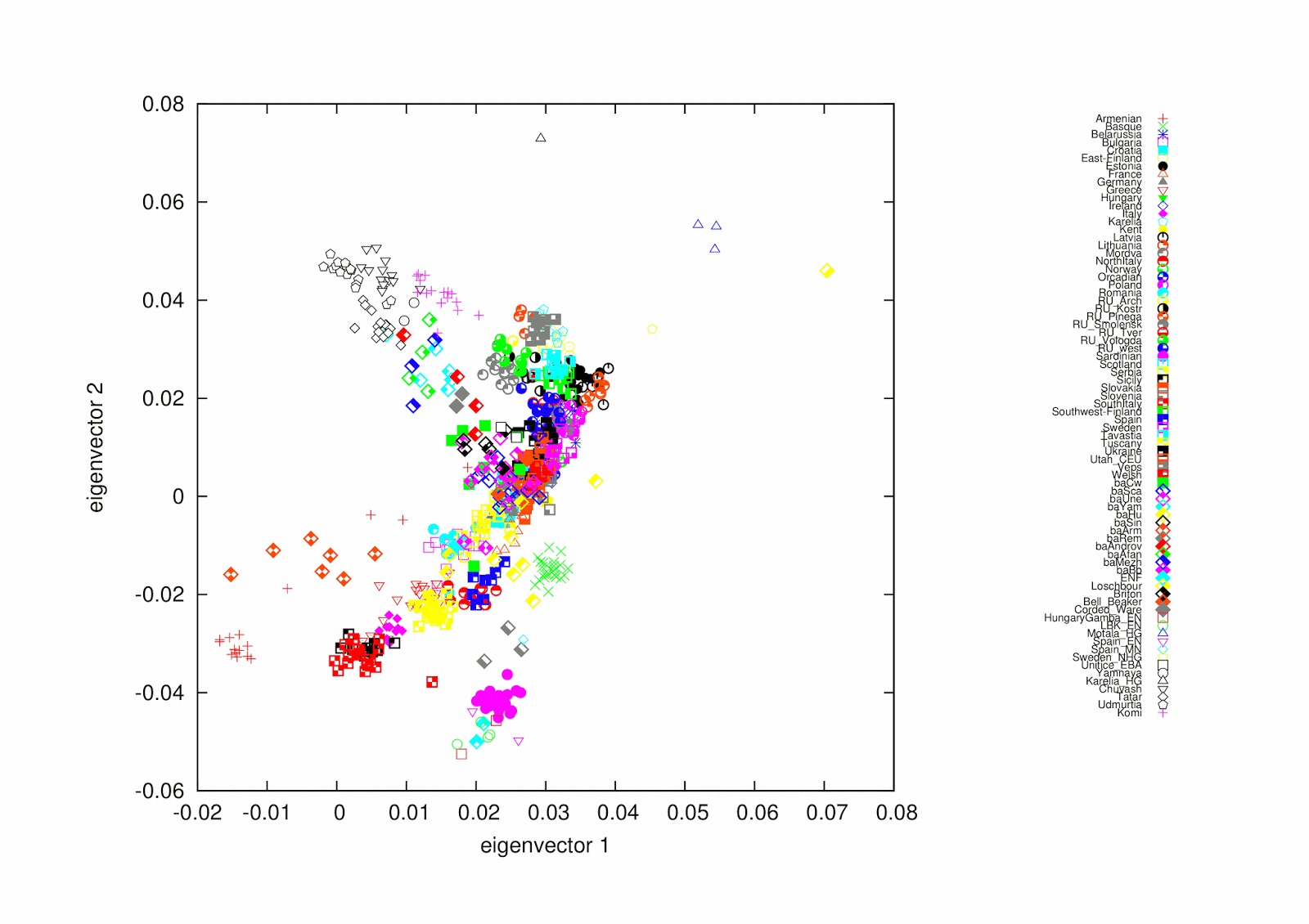


PCAs (or any other statistical analysis method, such as ADMIXTURE) are not indifferent to the "weight" of the various populations, hence sampling strategy is most important. For example I notice that from graph one, you have lots of North and NE Europeans and also some de-facto East Asians (Nenets, Mongola). These last clutter Dim1, which becomes a West-East axis that has more to do with Eurasia than with Europe specifically, and that's why typically they are excluded from Europe-focused analysis.
ReplyDeleteWhen you remove these last (second graph), the PCA is still cluttered by so many Eastern European samples of small populations that it's still all about NE Europeans, with the rest being redefined in NE European terms. It's not your typical Europe PCA, something very apparent in the absence of a Basque-Caucasus Dim2 polarity, that invariably appears in other less biased PCAs.
As you add again more extra-European populations the result reverts to pan-Eurasian analysis, which is of little interest to the understanding or our subcontinent. The third analysis says: India vs Europe (Dim1) and India vs Bedouin (Dim2). That's what a PCA can tell, not more.
Sampling strategy is almost everything in autosomal analysis. It can be used to twist the results but, if we want to do it properly, then we must:
(1) focus on what exactly we want to try to decipher. If we are trying to understand intra-European fine grain, then East Asians or any other external sample will bother us - unless what we are trying to understand is specifically East Asian admixture.
(2) Choose samples carefully. Personally I favor regular samples of large populations such as English, Italians, Russians, etc. and half-sized samples of key minor populations such as Basques, Sardinians, Finns. For example a sample I could use for Europe analysis could be: Spanish, French, English, German, Italian, Polish, Romanian, Russian each at n=10 (aprox.), Basque, Sardinians, Irish, Swedish, Latvian, Finnish, Greek, Sicilians and a Caucasian sample such as Tabassarans or Georgians, each at n=5. The difference in size is in order to allow actual larger populations not to be so excessively cluttered by smaller ones, what is just all kinds of wrong. You can use other apportions but trying to allow for proper representation of the large populations, not strictly proportional but something like logarithmically proportional (base 10) maybe.
(3) Any single approach is probably not enough to understand everything so different sampling strategies can be used to understand different aspects, producing different PCAs. Hence one with East Asians will illustrate East Asian admixture, one with lots of samples from whatever European region will illustrate the innards of that region (but be of little interest for pan-European analysis most often), etc.
I admit that the sampling strategy is important. This blog entry was done to show it, not to tell any truth. My main message was that drawing clines between ancient populations and between ancient and modern populations isn't easy. PCA never tells what it lacks of. I admit also that we have to look things from different angles using local and more global data sets.
DeleteI am not sure if it is a good strategy to weight more modern big populations, because they can be very homogeneous due to recent growth.
I can remove Nenets and Mongolians from the first PCA to see if they have the same effect than East Asians. Here is something that needs more analysing. Why East Asians added AFTER South Asians decrease the South Asian effect on ancient samples if the East Asian effect is smaller? Why this effect is not equal to modern Europeans. Whatever it is it is real on those plots.
Thinking more about sample sizes. It is also possible that big populations have grown via later migrations and are more mixed. So this is also an important aspect in deciding sample sizes. The result can be distorted if the mixing is more recent than used ancient samples.
Delete"I am not sure if it is a good strategy to weight more modern big populations, because they can be very homogeneous due to recent growth".
DeleteActually I'd expect North and South Germans, for example to be roughly as dissimilar as Poles and Hungarians. However the samples typically come from a single city or district, so you are probably right that they may behave as unnaturally homogeneous. Regardless, my point is to try to cover the geography and demography of the area under study in a way that tries to respect the patterns of reality. One can try different approaches but the key is to consciously attempt to reflect the diversity of the studied population. If unsure, trying different strategies will illustrate what changes they produce.
"It is also possible that big populations have grown via later migrations and are more mixed".
All that is speculative. The reality is more like ignoring populations like Finns because they belonged to Sweden or Russia or like Lithuanians because they belonged to Poland or Russia: using modern political borders as reference is a bit pointless. I'd rather use demographic densities and geographic distances. Also often the homogeneity is cross-border, for example Northern Europeans are surprisingly much like each other, much more than Southern Europeans (especially if we except "arctic anomalies" like Finns, etc.) So considering "populations" as defined by modern borders won't work. North Italians and South Italians are probably as different among them as Scots from Poles, maybe more.
"I can remove Nenets and Mongolians from the first PCA to see if they have the same effect than East Asians".
They should, at least in general terms. Mongola are an East Asian population and Nenets are only geographically Western, genetically they are clearly Eastern, with almost no admixture (the best preserved Uralic people of Europe in this aspect).
"Why East Asians added AFTER South Asians decrease the South Asian effect on ancient samples if the East Asian effect is smaller?"
The East Asian effect is much BIGGER: South Asians are closer to Europeans than East Asians are, this is known since the times of Cavalli-Sforza. Maybe if you had put more Indian samples or less West Eurasian samples... I've seen other analyses in which South Asians take naturally a third polarity in the Eurasian landscape, but there were many more South Asian samples.
North Italians and South Italians are more different from each other than Scots are from the Poles, but South Germans are much more similar to North Germans than Hungarians are to Poles.
DeleteNenets are neither unadmixed (they are a mix of East Eurasian and East European/Siberian hunter-gatherer ancestry) or preserved geographically as they came to European side of the Urals about a thousand years ago if not more recently, and they certainly are nothing like the proto-uralics from Volga-Kama region about 2000 b.c. Very likely also unlike the later proto-Samoyeds of the Sayan mountains.
I was interested in the difference in East Asian impact between ancient and modern samples, not the infuence in general. This proves that the history between ancient an modern samples includes something unknown yet.
DeleteI can assure you that the Finns have very little Russian admixture. Some Swedish admixture exists in Western Finland, but almost none in the east. We can simplify this by looking at ydna. I would say that Finnish admixture is in Sweden equally common than Swedish admixture in Finland.
"I can assure you that the Finns have very little Russian admixture".
DeleteDon't get me wrong: I just meant that political or conceptual borders, in this case historical ones, can deceive us about what is a "population". As Greisson mentions below: Russians, Italians and others have enough internal diversity to merit several samples. They also have the raw numbers to help keep the overall European picture compensated.
@Greisson: "Nenets are neither unadmixed (they are a mix of East Eurasian and East European/Siberian hunter-gatherer ancestry)"...
DeleteYou seem to be right. I realized that what I had in mind were actually Nganassan (see: http://forwhattheywereweare.blogspot.com/2011/12/playing-around-with-admixture.html), who are also Uralic but from Central-North Siberia (the easternmost surviving branch).
In any case the Nenets do have a strong IBD affinity with the Nganassan and align with rather "Asian", although transitional, peoples like the Dolgans, Yakuts, Tuvans, Khanty, Kets... (http://biorxiv.org/content/biorxiv/early/2015/04/30/018770.full.pdf). They seem not as extreme East Asian as the Nganassan but they do lean a lot to that polarity, so the effect is in general terms the same: PC1 of the first graphic above is taken by the East Asian or Siberian polarity.
"South Germans are much more similar to North Germans than Hungarians are to Poles"
I was tempted to write Czechs instead of Hungarians but whatever. Anyhow I do not think that all Germans are so similar. Certainly East Germans are intermediate, at least in Y-DNA, between West Germans and Poles and I would imagine that a Low Saxon is not at all indistinct from a Bavarian or Austrian. It's quite a big country from North to South, spanning half of the width of Europe at that longitude, and paleohistorically the North and the South did not share much (only in very few periods they had the same culture: Corded Ware and Germanic era).
Russia is a multiethnic country and can also offer different genetic views, one of those is closely related to Finns. But how the gene flow has gone, it is not a simple question. Something came from Russia to Finland and something from Finland to Russia.
DeleteMaju, it's Grelsson, not Greisson :)
DeleteI wouldn't say South Germans are extremely close to North Germans if I didn't know of some studies regarding the matter. Nelis et al (2009) already measured the fst-distances between North and South Germans, and they are smaller than even those between Czechs and Poles, certainly smaller than those between North Germans and Swedes. There is some North-South population structure, but far less significant than in Russia, Italy, Finland and even the UK (People of the British Isles project). The differences might have been larger in the Bronze Age (we don't have ancient DNA to verify) but if so, that structure has been lost by now.
Regarding Siberians, this might be illuminating:
D(Chimp, Pulliyar; Japanese, Ket) -0.0134 Z -5.324
D(Chimp, Paniya; Japanese, Ket) -0.0168 Z -6.6
This shows that these Dravidian-speaking South Indian groups who tend to have high levels of peak the South Indian component in admixture runs are in fact Japanese-shifted compared to Kets - makes sense because "Ancestral South Indian" appars to be some kind of East Eurasian. Adding West Siberians should thus not cause East Asian shift on the PCA in a more significant way than adding South Indian groups.
A final note about Nganasan: as a Samoyedic language it also is a recent arrival to its current territory, and the people are genetically similar to northern Paleo-Siberian language speakers such as Yukaghirs. These probably inhabited the area before and were assimilated to form the modern Nganasans. In a similar way another recent immigrant group to Siberia from the south, Yakuts, resembles their Tungusic-speaking neighbours more than their fellow Turkics in Mongolia, or Mongolians.
Grelsson: spelling noticed, my apologies.
DeleteI don't understand why you guys always change the original order of the Dstats formula (ref), which is D(H1,H2,H3,Chimpanzee), making it all very confusing.
Anyhow a strong negative score (-0.04 or greater in the original examples, I think your scores are too low but will ignore it by the moment) means that H3 is closer to H1 than to H2, so the reading of your stats is that Japanese are closer to Chimp than to South Indians if Kets are considered an outgroup. So it means that South Indians are closer to Kets than to Japanese (Kets being closer to South Indians than to Japanese cannot be deduced from your formulation, at least I don't know how). This corresponds naturally to the macro-South&West-Eurasian component that includes South Asian (ASI), West Eurasian and ANE (Ma1, AG) components. I disagree that ASI is closer to East Asian than to West Eurasian components: that's an artifact caused only by African-like (Basal Eurasian or genuine African) admixture in West Eurasians but not in South Asians (Makrani excepted).
The score is very very low in any case. For example in Green 2010, D(Han,San,French,Chimp)=-0.36 (Z=-72), which is much more clear. A less rotund but still significant score was D(French,San,Neandertal,Chimp)=-0.04 (Z=-9.3). But a D(San,Yoruba,Neandertal,Chimp)=-0.001 (Z=-0.4) was considered to imply no Neanderthal flow into Africans.
So if anything your result suggests very minor ASI flow (or equivalent) to Kets. And says nothing about Kets being closer to either South Indians or Japanese as such.
I reckon that Siberian genetics is a bit complicated and that not everything is merely East Asian. However there is an important East Asian element and pull and when Siberian specifics are not yet defined, Siberians tend to cluster with East Asians, see for example the K3 row in this ADMIXTURE graph from Sardana et al.. Western Siberians like Kets are more admixed, admittedly, but they have enough Eastern affinity to exert the same type of pull in a PCA; Mongola are almost 100% East Asian in that K=3 row. This is because, after the LGM, the main inflow into non-steppe Siberia came from that area, with very little coming from the West or Central Asia (except in the steppary strip).
This dstat indeed compares Japanese and Kets to South Indians , indicating that Japanese are closer South Indians.
DeleteIt doesn't matter where the outgroup is if other populations are in right places.
And the Z-value indicates the difference is statistically significant. |Z| > 3 is the threshold used in academic studies such as Lazaridis et al. (2014) and Haak et al (2015).
DeleteWhich is your reference to claim that? The equation is complex enough for me not to be able to decipher it, so I'd appreciate the acadamic reference.
DeleteIt's pretty simple and explained for instance in Green et al 2010 and Patterson et al 2010. Here's the gist: W , Y ; X , Z. If the result it negative, either Y is closer to X than to Z or W is closer to Z than to X. If it's positive, Y is closer to Z than to X or W closer to X. When one of them is a Chimp, an outgroup to all humans, and since there is no Chimp admixture in modern humans, a negative statistic means Y must be more related to X than it is to Z. So Japanese are closer to Paniya than Kets are and so on.
DeleteThis is an expected result and in line with ASI being some kind of East Eurasian.
ASI most definitely is not West Eurasian-related as it branched with Dai in the famous ANI/ASI paper for the record, it's either East Eurasian or nothing is East Eurasian.
I can't find Patterson 2010 (Patterson 2012, which Dienekes recommended, is about f3 stats - notice that Dienekes also places the outgroup in the 4th position). I have been using Green 2010 as reference all the time and it is not as simple as you say. To begin with the only comprehensive equation provided is a complex one. In any case, Green et al. always use a single standard order: (A,B,C,Chimp), where a negative stat indicates closeness between C and A, and a positive one that C is closer to B than to A. There's no semicolon, there's no explanation of what happens when you move the outgroup (chimp) around: they always compare C (H3) to the first pair (A,B or, in the original H1,H2).
DeleteI don't know if your interpretation is right but I know I cannot confirm it.
That ASI "branches with Dai" is only because of "Basal Eurasian" (African-like) influence into the overall West Eurasian genome, something that does not affects pre-Neolithic Indians. It's an artifact and illustrates the limits of using autosomal genetics without full understanding of what is actually at play. That's why I generally prefer using haploid genetics when diving so deep in time: they provide a much cleaner picture. In order to make deep-time autosomal analyses that are meaningful, we need first to get enough ancient genomes from all around the world and then analyze moderns based on those ancient genomes. That's so far science-fiction only, not just because all those genomes are still awaiting sequencing but also because, when sequenced, they are often too fragmentary to allow for this kind of analysis.
It doesn't matter where the outgroup is, D-stats work as I say and that's how they are used by everyone. Japanese are indeed closer to Paniya and Pulliyar than Ket are. ASI branches with Dai because it is East Eurasian and not West Eurasian. West Eurasians that are not supposed to have Basal are Western HG and Ancient North Eurasian, neither of which branch with ASI or are interchangeable with it. Even some Gujarati samples (C and D) are fitted as up to 28% Dai, as per qpAdm tests of genome blogger Davidski. https://drive.google.com/file/d/0B9o3EYTdM8lQcVhXNVM3RXJqWm8/view?usp=sharing
DeleteThese are much more "west eurasian" than Paniya and Pulliyar. No Indian groups can be fitted without Dai or other East Eurasian reference, and that is because ASI is East Eurasian.
As D-stats work like I said, the place of the outgroup has no effect:
Ket Pulliyar Japanese Chimp -0.0134 -5.324
Ket Paniya Japanese Chimp -0.0168 -6.6
Still Japanese closer to South Indians.
Also a negative stat does not indicate closeness of A and C, it is either B and C or A and D. Positive is A and C or B and D.
DeleteNo, no:
DeleteYou say:
"Ket Pulliyar Japanese Chimp -0.0134" → "Japanese closer to South Indians" [(Pulliyar) than to Kets]
Green 2010 says:
"D(Han,San,French,Chimp)=-0.36" French closer to Han than to San
These claims are contradictory and choosing between you and Green 2010, I must choose the latter. Your result as described with the Chimp outgroup in the fourth position clearly states that Japanese are closer to Kets than to Pulliyar and Paniya South Indian peoples.
Sometimes "everyone" do things incorrectly, for example there's a lot of people who believe in "creationism", in spite of going against all scientific evidence. Just because "everyone" does, it does not mean it is correct.
The D-stats of ADMIXTOOLS follow the format of Patterson et al. 2012 which work as I said
Delete"We confirm this using the statistic D(San, Karitiana;French,Italian), which has a Z-score of −6.4 on the Illumina 650Y SNP array panel and −3.5 on our population genetics panel ascertained with a San heterozygote. These results show that the Karitiana are significantly more closely related to the French than to the Italians. The ‘Italian’ samples here are from Bergamo, northern Italy."
If a negative statistics here meant, contrary to what Patterson says, that A and C are closer then LBK would be much closer to sub-saharans than a hunter-gatherer from Caucasus: Hadza Kotias LBK_EN Chimp -0.2986 -79.619
This is obviously untrue.
So, negative statistic means B is closer to C than to D, as I said. Similarly Japanese are significantly closer to Paniya/Pullyar than to Ket. Drop the creationism comparisons, this is not a matter of faith.
Maybe Green uses some other program, but Eigensoft's qpDstat, the program also I use, works like Grelsson figured
Delete"The output of qpDstat is informative about the direction of gene flow. So for 4 populations (W, X, Y, Z) as follows -
If the Z-score is +ve, then the gene flow occured either between W and Y or X and Z
If the Z-score is -ve, then the gene flow occured either between W and Z or X and Y. "
https://github.com/DReichLab/AdmixTools/blob/master/README.Dstatistics
What can we learn here? Only that softwares do what the makers make them do. There are no rules.
Thank you, M., I stand corrected (a reference like that was what I was looking for).
DeleteIt may still mean "Basal Eurasian" gene flow to Kets... That's an interesting issue because somehow "Basal Eurasian" seems to be involved irregularly with Western Eurasians (which include Ma1 and therefore largely Kets). The recent finding of Caucasus HGs being (according to the paper) 100% within the "Basal Eurasian" category is very curious in this regard. On the other hand WHGs seem to totally like that element (totally?) and then Davidski seems to have found pre-Motala admixture in CHGs. The Eurasia-Africa crossroads is getting very complicated.
New CHG samples are really interesting, especially regarging European hunter-gatherers. I still wait for more information and perhaps someone is going to make usable genotype files. The link in Jones et al. gives only large sequence files and for some time I have no time to process them. I started now another project with a new software, let it be a secret until I have something ready.
DeleteBasal Eurasian is supposed to be equally divergent from East and West Eurasians so it's neutral here. Flegontov et al suggests Kets are a simple mix of ANE and East Eurasian, and neither ANE or WHG have Basal Eurasian. Chimp outgroup wouldn't have Basal affinities anyway, so this East Asian-South Indian connection is quite straightforward.
DeleteNo if Kets carry Basal Eurasian. In fact it's impossible to argue that South Asians and East Asians are closer than West (or Central) Eurasians unless these carry something that is not mainline Asian genetics, something that is "African-like", something that either migrated from Africa into West Eurasia or was just here (in the Persian Gulf marshy "oasis" maybe) since OoA times. For example the phylogenetic position of Y-DNA G (extremely upstream within F and very common precisely in the Caucasus) could be related to that ancient basal component. Otherwise people just migrated to further (South and East) Asia and later back-migrated to the West, as it is apparent in Y-DNA K2, among other stuff (mtDNA N/R too, Y-DNA C and F→HIJK→IJK→IJ even), as well as in the most up-to-date archaeology.
Delete"Chimp outgroup wouldn't have Basal affinities anyway"...
DeleteIt doesn't matter: it acts as quasi-root for all Humankind, you could use a giraffe or Lucy's genome or the most remote African HG sample. That's what an outgroup does: act as root-like reference. So anything between upstream of the shared triple root is partly present as Chimp affinity, even if tiny.
A counter-test could be using other less radically basal outgroups to see where the trend is broken, if at all. For example sequentially testing for Mbuti, Yoruba, Dinka, Bedouin as "outgroups".
Maybe Yemeni Jewish instead of Bedouins, because Naqab Bedouins seem to have minor true African admixture, while Yemeni Jews probably not (that's the only difference between Yemeni Jews and mainline Yemenis).
DeleteIt's not at all impossible, as ASI is a type of East Eurasian it just depends on the amount a population has. Gujaratis are not closer to Japanese than Kets but Paniya and Pulliyar are - and that is simply because the latter are more East Eurasian. There's no need to add mystery meat to the mix, we already have a good idea about Kets from various studies and it involves no Basal Eurasian.
DeleteThis is a good qpAdm model from Eurogenes for Gujarati A (very "western" Indian group
Unetice_EBA 64,7%
Satsurblia 21,3%
Dai 14%
But some other Gujarati samples, ones with more "South Indian" can be modelled like this:
MA-1 13%
Satsurblia 59,5%
Dai 27,5%
The latter Gujarati group would be closer to Japanese than the former, but not nearly as close as extreme South Indians like Pulliyar. And why can they be modelled as Dai, but all models without East Eurasian fail? It's because qpAdm is based on f4-statistics which ignore recent drift (like D-stat), and drift is what separates their "ASI" from Dai.
Any Basal Eurasian in modern populations is as distant from chimps as East Eurasian, WHG or whatever, because it has drifted from the common human-chimp ancestor as long. That is why Chimp cannot have Basal Eurasian affinities and is a neutral outgroup in this regard.
Russia, Finland, Italy and France need regional samples because these countries have genuine differences between subpopulations, beyond drift.
ReplyDeleteRe: non-european sampling, Nenets have enough European hunter-gatherer-like ancestry to the exclusion of East Asians that their effect is not de facto East Asian. This is easily seen with D(X, Mbuti; Dai/Han, Loschbour), comparing with South Asians. Mongolians may be more East Asian.
Yeah, I agree. I would add also Iberians if we spot on North Europe. One of the most difficult decision is whom shoudl we take fro Northwets Europe. There are many homogeneous populations, like Norwegians, Icelanders, Scots, Irishmen, Orcadians. I have used Brits from Kent to get more diversity.
Delete